

جبر با الگوریتم های pca با متلب
قسمت اول
در این بخش قصد داریم تا با مبحث PCA و چگونگی ترسیم خط PCA آشنا شویم. خط PCA را جایی گوییم که بهترین خط برای نگاشت داده های دو بعدی در یک بعد است.
الف
کد زیر مربوط به این قسمت از تمرین است که ابتدا داده ها را نرمال سازی میکند. سپس بردارهای ویژه را از روی داده های آموزشی پیدا کرده و سپس خطی که PCA داده ها رو روی نگاشت خواهد کرد را پیدا میکنیم.
تعداد داده هایی که باید تولید شوند
NumberofData = 1000;تولید نمونه ها
Mean1 = [10;10];میانگین کلاس دوم
Cov1 = [4,4;4,9];
Cov2 = Cov1 ;
کواریانس دو کلاس
% ------------------------------------------- >
Class1 = mvnrnd(Mean1,Cov1,NumberofData);
Class2 = mvnrnd(Mean2,Cov2,NumberofData);ذخیره همه داده ها در یک متغیر
AllData = [Class1;Class2];
% ------------------------------------------- >نرمال سازی داده ها
AllData = AllData - mean(AllData);محاسبه حداقل و حداکثر داده ها برای ترسیم خط
RangeOfData = [min(AllData(:,1)) max(AllData(:,1))];
% ------------------------------------------- >محاسبه کواریانس
Cov1 =( AllData'*AllData)./(size(AllData,1)-1);پیدا کردن مقادیر ویژه و بردار ویژه
[V,D] = eig(Cov1);مرتب سازی مقادیر ویژه
EigVal = diag(D);
[~,Index] = sort(EigVal,'descend');مرتب کردن بردارهای ویژه بر حسب مقادیر ویژه
EigenVectors = V(:,Index);
% ------------------------------------------- >با استفاده از اولین بردار ویژه که همان اولین مولفه PCA را نشان میدهد اقدام به پیدا کردن شیب خط میکنیم.
m = EigenVectors(2)/EigenVectors(1);تابعی برای ترسیم خط PCA
PlotFunc = @(x)m*x;خروجی این قسمت به شکل زیر خواهد بود. خط pca باید در راستای حداکثر واریانس داده ها باشد و داده ها سپس با یک تبدیل خطی بر حسب اولین بردار ویژه روی این خط نگاشت میشوند.
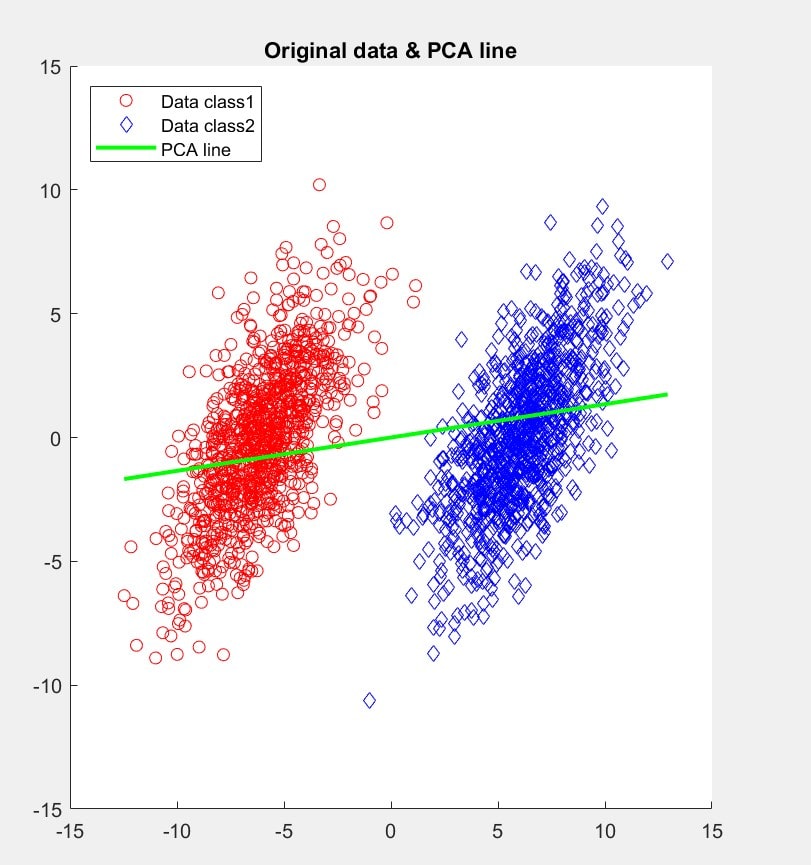
ب)
کدهای زیر مربوط به نگاشت داده ها روی PCA است.
انتخاب اولین بردار ویژه
EigenVector = EigenVectors(:,1);پیدا کردن مقادیر ویژه و بردار ویژه
[V,D] = eig(Cov1);مرتب سازی مقادیر ویژه
EigVal = diag(D);
[~,Index] = sort(EigVal,'descend');مرتب کردن بردارهای ویژه بر حسب مقادیر ویژه
EigenVectors = V(:,Index);
% ------------------------------------------- >با استفاده از اولین بردار ویژه که همان اولین مولفه PCA را نشان میدهد اقدام به پیدا کردن شیب خط میکنیم.
m = EigenVectors(2)/EigenVectors(1);نمودار خروجی حاصل از تقریب به صورت زیر خواهد شد. مشحص است که هر چه مقدار تقریب بیشتر میشود، خطا نیز کاهش میابد و به سمت صفر میل میکند. دلیل اینکه در تقریب های مرتبه پایین خطای بیشتری داریم این است که در تقریب های مرتبه پایین ، اطلاعات بسیار زیادی از عکس را دور میریزیم و همین امر باعث خطا میشود.
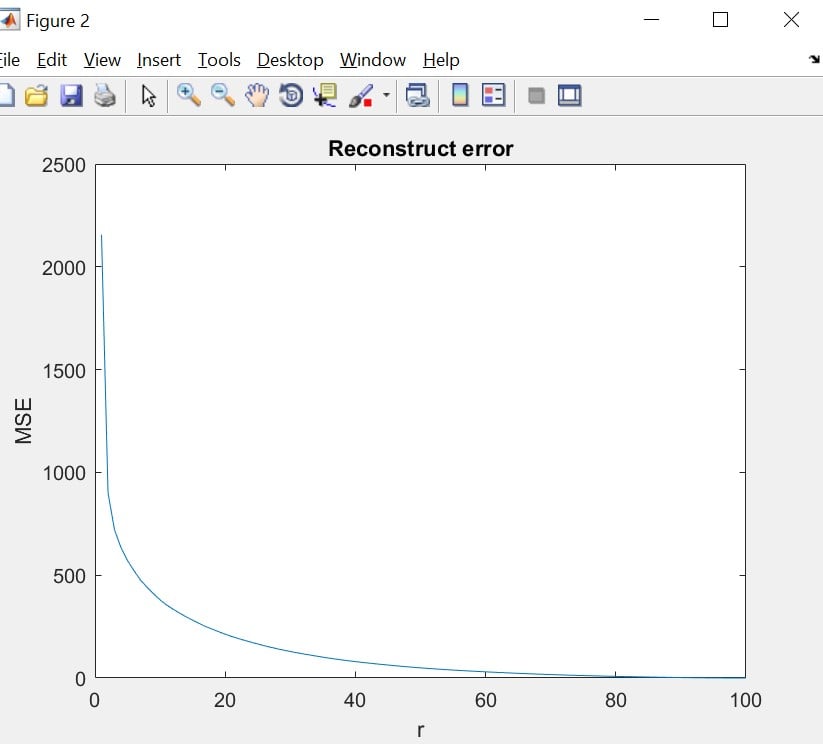
امتیازی
از قبل ماتریس P که همان تصاویر ویژه هست را پیدا کرده بودیم. حال با استفاده از این ماتریس داده ها را به ابعاد پایین تر نگاشت میکنیم. سپس با همین ماتریس تصاویر ویژه دوباره عکس را بازسازی میکنیم و خطای بازسازی را محاسبه میکنیم
به ازای مقادیر مختلف r مسئله را به مقدار r کاهش بده با استفاده از تصاویر ویژه
for r = 1 : 2500
fprintf('r = %d\n',r);تابع مد نظر برای کاهش ابعاد داده های تست و آموزش
[F,FTest]= Func1(TrainImageDataset2,TestImageDataset2,EigenVectors,r);بازسازی دادده ها با استفاده از ماتریس تصاویر ویژه
ReconstruceTrainDataset2 = F* EigenVectors(:,1:r)';محاسبه خطای بازسازی
TrainRecError(r) = mse(TrainImageDataset2,ReconstruceTrainDataset2);
ReconstruceTestDataset2 = FTest* EigenVectors(:,1:r)';
TestRecError(r) = mse(TestImageDataset2,ReconstruceTestDataset2);
Endنمایش نمودار خطای بازسازی
figure;
plot(TrainRecError,'r');
hold on;
plot(TestRecError,'b');
title('Reconstruct error');
xlabel('r');
ylabel('MSE');
legend('TrainRecError','TestRecError');
drawnow;endتابع کاهش ابعاد. در این تابع دو دیتای آموزش و تست را میگیریم و با استفاده از تبدیل خطی و به کمک ماتریس تصاویر ویژه ابعاد را کاهشم میدهیم و خروجی آن دو دیتای کاهش یافته به اسامی F و FTest است
function [F,FTest] = Func1(DataTrain,DataTest,Vec,r)
F = DataTrain * Vec(:,1:r);
FTest = DataTest * Vec(:,1:r);
endخروجی حاصل از خطای بازسازی داده ها با استفاده از تصاویر ویژه
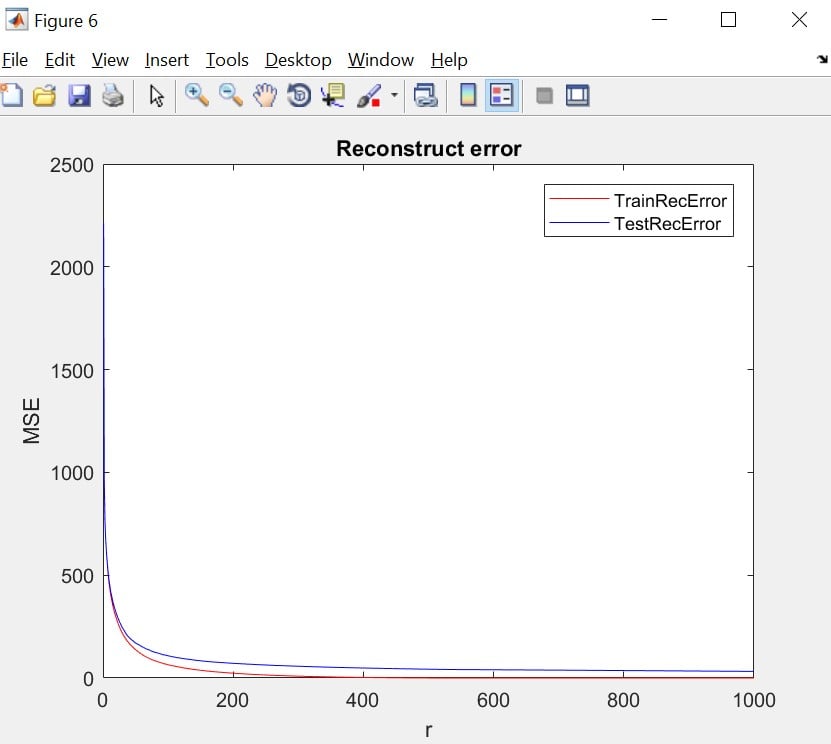
در شکل بالا خط قرمز مربوط به خطای بازسازی داده های آموزش است و خط آبی مربوط به خطای تست است. مشخص است که هر چقدر کاهش ابعاد بیشتر باشد، خطای مسئله بالاتر خواهد بود که در اوایل نمودار متوجه این موضوع میشویم. نتیجه مهمی که از این نمودار میتوان گرفت این است که نیازی به استفاده از داده های با ابعاد 2500 بعدی نیست. بلکه با توجه به نمودار بالا میتوانیم بگوییم که تنها با استفاده از حدود 150 بعد (به صورت تقریبی جایی که نمودار از حالت نزول شارپی خارج میشود و به یک حالت مسطح میرسد) میتوانیم داده های اصلی را بازسازی کنیم پس با همین 150 مولفه میتوانیم برای مدل های یادگیری ماشین نیز استفاده کنیم. استفاده از مسئله با ابعاد 150 سرعت انجام محاسبات را بسیار کاهش خواهد داد نسبت به زمانی که ابعاد مسئله 2500 بعدی باشد.
- در متلب نسخه های جدید اجرا شود.
- دو سوال آخر تمرین به دلیل حجم زیاد محاسبات زمان بر است پس تا پایان اجرای برنامه شکیبا باشید.
- آخرین بخش تمرین که امیتازی است به علت اینکه زمان اجرا برای 2500 حلقه بسیار زیاد میشود، تنها از 1000 تکرار استفاده کرده ایم. سایر تکرار ها تاثیری در روند نمودار نخواهند داشت و خطای بازسازی نزدیک به صفر خواهد بود.
- فایل faces و دو فایل متنی حتما باید در کنار کدها باشند.
- برای اجرای قسمت اول ، فایل اجرایی Problem1 را اجرا کنید و برای اجرای قسمت دوم از فایل اجرایی Problem2
- تابع ذکر شده در سوال امتیازی همان تابع Func1 است که در پایان فایل اجرایی Probelm2 وجود دارد.
تمامی فایل ها و کدهای مورد نیاز این پروژه در فایل روبرو موجود می باشد، لطفا دانلود کرده و لذت ببرید.




